Reading notes of The Principle of Diffusion Models
This note is to summarize key points, note down key formulae and gives some discussion for the book “The Principle of Diffusion Models” by Song et al.
1. Deep Generative Modeling
TODO.
2. Variational Perspective: From VAEs to DDPMs
2.1 Variational Autoencoder
Model structure
\[ x\xrightarrow{\mathrm{encoder},q_{\theta}(z|x)} z\sim \mathcal{N}(0,1) \xrightarrow{\mathrm{decoder}, p_{\phi}(x|z)} \hat{x} \]
Key formulae
The learned data distribution:
\[ p_{\phi}(x) = \mathbb{E}_{p(z)}[p_{\phi}(x|z)] = \int p_{\phi}(x|z)p(z)dz \]
Intractable to compute due to integral over latent variable \(z\).
Maximizing log-likelihood \(\iff\) minimizing the KL divergence between true data distribution \(q(x)\) and learned data distribution \(p_{\phi}(x)\):
\[ \begin{aligned} \arg\max_{\phi} \mathbb{E}_{q(x)}[\log p_{\phi}(x)] &\iff \arg\min_{\phi} \mathbb{E}_{q(x)}[\log q(x) - \log p_{\phi}(x)] \\ &\iff \arg\min_{\phi} \mathrm{KL}(q(x) || p_{\phi}(x)) \end{aligned} \]
Evidence Lower Bound (ELBO)
Core Idea:
We try to estimate \(p_{\phi}(x)\) by Bayes’ theorem
\[ p_{\phi}(x) = \frac{p_{\phi}(x,z)}{p_{\phi}(z|x)} \]
Now the posterior \(p_{\phi}(z|x)\) is also intractable, so we introduce a variational distribution \(q_{\theta}(z|x)\) to approximate it.
Proof of being lower bound of the log-likelihood \(\log p_{\phi}(x)\):
\[ \begin{aligned} \log p_{\phi}(x) &= \mathbb{E}_{q_{\theta}(z|x)}\left[\log \frac{p_{\phi}(x,z)}{p_{\phi}(z|x)}\right] \\ &= \mathbb{E}_{q_{\theta}(z|x)}\left[\log \frac{p_{\phi}(x,z)}{q_{\theta}(z|x)} \cdot \frac{q_{\theta}(z|x)}{p_{\phi}(z|x)}\right] \\ &= \mathbb{E}_{q_{\theta}(z|x)}\left[\log \frac{p_{\phi}(x,z)}{q_{\theta}(z|x)}\right] + \mathbb{E}_{q_{\theta}(z|x)}\left[\log \frac{q_{\theta}(z|x)}{p_{\phi}(z|x)}\right] \\ &= \mathbb{E}_{q_{\theta}(z|x)}\left[\log \frac{p_{\phi}(x,z)}{q_{\theta}(z|x)}\right] + \mathrm{KL}(q_{\theta}(z|x) || p_{\phi}(z|x)) \\ &\geq \mathbb{E}_{q_{\theta}(z|x)}\left[\log \frac{p_{\phi}(x,z)}{q_{\theta}(z|x)}\right] \\ &= \underbrace{\mathbb E_{q_{\theta}(z|x)}\left[\log p_{\phi}(x|z)\right]}_{\text{Reconstruction Term}} - \underbrace {\mathrm{KL}(q_{\theta}(z|x) || p(z))}_{\text{Latent Regularization}}\\ &= \mathcal{L}(\theta, \phi; x) \end{aligned} \]
Quick summary:
By introducing a latent variable \(z\) and an inaccurate posterior approximation \(q_{\theta}(z|x)\), we derive a lower bound of the log-likelihood \(\log p_{\phi}(x)\), which is called Evidence Lower Bound (ELBO).
Interpretation 1.
It is the expectation of the Bayes-like ratio \(\frac{p_{\phi}(x,z)}{q_{\theta}(z|x)}\) by replacing the intractable true posterior \(p_{\phi}(z|x)\) with the variational distribution \(q_{\theta}(z|x)\).
Interpretation 2.
It consists of two terms: a reconstruction term that encourages the decoder to reconstruct \(x\) from \(z\), and a latent regularization term that encourages the encoder distribution \(q_{\theta}(z|x)\) to be close to the prior \(p(z)\).
Reason of blurriness of Standard VAE
The standard VAE employs Gaussian distribution for both encoder and decoder.
\[ \begin{aligned} q_{\theta}(z|x) &= \mathcal{N}(z; \mu_{\theta}(x), \sigma_{\theta}^2(x)I)\\ p_{\phi}(x|z) &= \mathcal{N}(x; \mu_{\phi}(z), \sigma^2 I) \end{aligned} \]
The optimal decoder mean \(\mu_{\phi}(z)\) is the conditional expectation \(\mathbb{E}[x|z]\), which is the average of all possible \(x\) that can be mapped to the same \(z\). This averaging effect leads to blurriness in generated samples.
Derivation of optimal decoder mean:
First note that \[ \begin{aligned} \mathbb{E}_{q_{\theta}(z|x)}[\log p_{\phi}(x|z)] &= \mathbb{E}_{q_{\theta}(z|x)}\left[-\frac{1}{2\sigma^2}\|x - \mu_{\phi}(z)\|^2 + \text{const}\right] \\ &= -\frac{1}{2\sigma^2} \mathbb{E}_{q_{\theta}(z|x)}[\|x - \mu_{\phi}(z)\|^2] + \text{const} \\ \end{aligned} \]
And take expectation over \(p(x)\):
\[ \begin{aligned} \mathbb{E}_{p(x)}[\mathbb{E}_{q_{\theta}(z|x)}[\log p_{\phi}(x|z)]] &= -\frac{1}{2\sigma^2} \mathbb{E}_{p(x)}[\mathbb{E}_{q_{\theta}(z|x)}[\|x - \mu_{\phi}(z)\|^2]] + \text{const} \\ &= -\frac{1}{2\sigma^2} \mathbb{E}_{q_{\theta}(z)}[\mathbb{E}_{q_{\theta}(x|z)}[\|x - \mu_{\phi}(z)\|^2]] + \text{const} \\ \end{aligned} \]
where \(q_{\theta}(x|z)= \frac{p(x) q_{\theta}(z|x)}{q_{\theta}(z)}\) is the posterior distribution of \(x\) given \(z\) under the encoder.
For the inner expectation \(\mathbb{E}_{q_{\theta}(x|z)}[\|x - \mu_{\phi}(z)\|^2]\), it is minimized when \(\mu_{\phi}(z) = \mathbb{E}_{q_{\theta}(x|z)}[x]\).
Think: Which part of the structure of VAE leads to blurriness most?
Encoder or Decoder?
Answer:
It depends on your perspective.
The encoder mixes different \(x\) into the same \(z\), create ambiguity. The Gaussian assumption of \(z\) enforces this mixing, otherwise the aggregate posterior \(q_{\theta}(z)=\int p(x) q_{\theta}(z|x) dx\) cannot match the simple prior \(p(z)\).
The Gaussian decoder reconstructs the average of these ambiguous \(x\), leading to blurriness.
2.1.5 Hierarchical VAE
Model structure
\[ x \xLeftrightarrow[\mathrm{decoder}, p_{\phi}(x|z_1)]{\mathrm{encoder}, q_{\theta}(z_1|x)} z_1 \xLeftrightarrow[\mathrm{decoder}, p_{\phi}(z_1|z_2)]{\mathrm{encoder}, q_{\theta}(z_2|z_1)} z_2 \xleftrightarrow{}\cdots \xLeftrightarrow[\mathrm{decoder}, p_{\phi}(z_{L-1}|z_L)]{\mathrm{encoder}, q_{\theta}(z_L|z_{L-1})}z_L \]
Key formulae
Distributions \[ \begin{aligned} p_{\phi}(x, z_{1:L}) &= p_{\phi}(x|z_1) \prod_{i=1}^{L-1} p_{\phi}(z_i|z_{i+1}) p(z_L) \\ p_{\phi}(x) &= \int p_{\phi}(x, z_{1:L}) dz_{1:L}\\ q_{\theta}(z_{1:L}|x) &= q_{\theta}(z_1|x) \prod_{i=1}^{L-1} q_{\theta}(z_{i+1}|z_i) \\ \end{aligned} \]
ELBO
\[ \begin{aligned} \log p_{\phi}(x) &\geq \mathbb{E}_{q_{\theta}(z_{1:L}|x)}\left[\log \frac{p_{\phi}(x, z_{1:L})}{q_{\theta}(z_{1:L}|x)}\right] \\ &= \mathbb{E}_{q_{\theta}(z_{1:L}|x)}\left[\log \frac{p_{\phi}(x|z_1) \prod_{i=2}^{L} p_{\phi}(z_{i-1}|z_{i}) p(z_L)}{q_{\theta}(z_1|x) \prod_{i=2}^{L} q_{\theta}(z_{i}|z_{i-1})}\right] \\ &= E_q\left[\log p_{\phi}(x|z_1)\right] - E_q\left[\mathrm{KL}(q_{\theta}(z_L|z_{L-1}) || p(z_L))\right] - \sum_{i=2}^{L-1} E_q\left[\mathrm{KL}(q_{\theta}(z_{i}|z_{i-1}) || p_{\phi}(z_{i}|z_{i+1}))\right] - E_q\left[\mathrm{KL}(q_{\theta}(z_1|x) || p_{\phi}(z_1|z_2))\right] \\ \end{aligned} \] where \(\mathbb E_q\) means \(\mathbb E_{p(x) q_{\theta}(z_{1:L}|x)}\).
2.2 Denoising Diffusion Probabilistic Models
Model structure
\[ x_0 \xLeftrightarrow[\mathrm{denoising}, p_{\phi}(x_{0}|x_1)]{\mathrm{add \ noise}, q(x_1|x_{0})} x_1 \xLeftrightarrow[\mathrm{denoising}, p_{\phi}(x_{1}|x_2)]{\mathrm{add\ noise}, q(x_2|x_{1})} x_2 \xLeftrightarrow{}\cdots \xLeftrightarrow[\mathrm{denoising}, p_{\phi}(x_{T-1}|x_T)]{\mathrm{add\ noise}, q(x_{T-1}|x_T)} x_T \]
\[ \begin{aligned} p(x_i|x_{i-1}) &= \mathcal{N}(x_i; \sqrt{1-\beta_i^2} x_{i-1}, \beta_i^2 I) \\ x_i &= \alpha_i x_{i-1} + \beta_i \epsilon_{i}, \quad \epsilon_{i} \sim \mathcal{N}(0, I) \\ p_i(x_i|x_0) &= \mathcal{N}(x_i; \bar{\alpha}_i x_0, (1-\bar{\alpha}_i^2) I) , \quad \bar{\alpha}_i = \prod_{k=1}^{i} \sqrt{1-\beta_k^2} = \prod_{k=1}^{i} \alpha_k\\ x_i &= \bar{\alpha}_i x_0 + \sqrt{1-\bar{\alpha}^2_i} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) \\ \end{aligned} \]
Here “=” means equality in distribution.
Note: > The DDPM paper uses \(\sqrt{1-\beta_i}\) instead of \(\sqrt{1-\beta_i^2}\), so whenever see \(\beta_i\) in this note, it means the one in DDPM paper squared. And the \(\bar \alpha_i\) here is also different from DDPM paper by squaring.
Idea
The forward process gradually adds Gaussian noise to the data \(x_0\) until it is nearly pure Gaussian noise \(x_T\sim \mathcal{N}(0, I)\).
We want to learn the reverse denoising process \(p_{\phi}(x_{i-1}|x_i)\) to recover data from noise.
\[ \begin{aligned} \mathbb E_{p_i(x_i)} \left[\mathrm{KL}(p_i(x_{i-1}|x_i) || p_{\phi}(x_{i-1}|x_i))\right] &= \int p_i(x_i) \int p_i(x_{i-1}|x_i) \log \frac{p_i(x_{i-1}|x_i)}{p_{\phi}(x_{i-1}|x_i)} dx_{i-1} dx_i\\ &= \int \int p_i(x_i | x_{i-1}) p_i(x_{i-1}) \log \frac{p_i(x_{i}|x_{i-1})p(x_{i-1})}{p_{\phi}(x_{i-1}|x_i)p(x_i)} dx_{i-1} dx_i\\ \end{aligned} \]
But estimate \(p_i(x_i) = \int p_i(x_i|x_0) p(x_0) dx_0\) is intractable.
We turn to \[ p(x_{i-1}|x_i, x_0) = \frac{p_i(x_i|x_{i-1}, x_0) p_i(x_{i-1}|x_0)}{p_i(x_i|x_0)} = \frac{p_i(x_i|x_{i-1}) p(x_{i-1}|x_0)}{p_i(x_i|x_0)} \] which is tractable since all distributions are Gaussian.
Then we have \[ \begin{aligned} &\mathbb E_{p_i(x_i)} [\mathrm{KL}(p_i(x_{i-1}|x_i) || p_{\phi}(x_{i-1}|x_i))] \\ = &\mathbb E_{p(x_0) p_i(x_i|x_0)} [\mathrm{KL}(p_i(x_{i-1}|x_i, x_0) || p_{\phi}(x_{i-1}|x_i))] + C \end{aligned} \]
Claim:
The minimizer of both is \(p(x_{i-1}|x_i)\).
Proof: \[ \begin{aligned} \mathbb E_{p(x_0, x_i)} [\mathrm{KL}(p_i(x_{i-1}|x_i, x_0) || p_{\phi}(x_{i-1}|x_i))] &= \int \int \int p(x_0, x_i) p(x_{i-1}|x_i, x_0) \log \frac{p(x_{i-1}|x_i, x_0)}{p_{\phi}(x_{i-1}|x_i)} dx_{i-1} dx_i dx_0 \\ &= \int p(x_i) \int p(x_0|x_i) \int p(x_{i-1}|x_i, x_0) \log \frac{p(x_{i-1}|x_i, x_0)}{p_{\phi}(x_{i-1}|x_i)} dx_{i-1} dx_0 dx_i \\ &= \mathbb E_{p(x_i)} \left[\mathbb E_{p(x_0|x_i)}\left[\mathbb E_{p(x_{i-1}|x_i,x_0)}\left[\log\frac{p(x_{i-1}|x_i,x_0)}{p_{\phi}(x_{i-1}|x_i)}\right]\right]\right]\\ &= \mathbb E_{p(x_i)} \left[\mathbb E_{p(x_0|x_i)}\left[\mathbb E_{p(x_{i-1}|x_i,x_0)}\left[\log \frac{p(x_{i-1}|x_i,x_0)}{p(x_{i-1}|x_i)}\right] \right]\right] + \mathbb E_{p(x_i)} \left[\mathbb E_{p(x_0|x_i)}\left[\mathbb E_{p(x_{i-1}|x_i,x_0)}\left[\log \frac{p(x_{i-1}|x_i)}{p_{\phi}(x_{i-1}|x_i)}\right] \right]\right]\\ &= \mathbb E_{p(x_i)} \left[\mathbb E_{p(x_0|x_i)}\left[\mathrm{KL}(p(x_{i-1}|x_i,x_0) || p(x_{i-1}|x_i))\right]\right] + \mathbb E_{p(x_i)} \left[\mathrm{KL}(p(x_{i-1}|x_i) || p_{\phi}(x_{i-1}|x_i))\right]\\ \end{aligned} \]
Note the first term is independent of \(p_{\phi}\), so minimizing the whole expression is equivalent to minimizing the second term.
And the second term is minimized when \(p_{\phi}(x_{i-1}|x_i) = p(x_{i-1}|x_i) = \mathbb{E}_{p(x_0|x_i)}[p(x_{i-1}|x_i, x_0)]\).
The above argument shows that minimizing the KL divergence between marginal distributions is mathematically identical to minimizing the KL divergence between specific conditional distributions.
This is very powerful and we will see similar conditional techniques again in flow-based models.
Closed form of \(p(x_{i-1}|x_i, x_0)\):
By Bayes’ theorem and Markov property,
\[ p(x_{i-1}|x_i, x_0) = \frac{p_i(x_i|x_{i-1}, x_0) p_i(x_{i-1}|x_0)}{p_i(x_i|x_0)} = \frac{p_i(x_i|x_{i-1}) p(x_{i-1}|x_0)}{p_i(x_i|x_0)} \propto p_i(x_i|x_{i-1}) p_i(x_{i-1}|x_0) \]
\[ \begin{aligned} p_i(x_i|x_{i-1}) &= \mathcal{N}(x_i; \sqrt{1-\beta_i^2} x_{i-1}, \beta_i^2 I) \propto \mathcal{N}(x_{i-1}; \frac{1}{\sqrt{1-\beta_i^2}} x_i, \frac{\beta_i^2}{1-\beta_i^2} I) \\ p_i(x_{i-1}|x_0) &= \mathcal{N}(x_{i-1}; \bar{\alpha}_{i-1} x_0, (1-\bar{\alpha}_{i-1}^2) I) \\ \end{aligned} \]
Formulas of Gaussian multiplication give \[ \begin{aligned} \Sigma^{-1} &= \Sigma_1^{-1} + \Sigma_2^{-1}\\ \mu &= \Sigma(\Sigma_1^{-1} \mu_1 + \Sigma_2^{-1} \mu_2) \end{aligned} \]
So we have \[ \begin{aligned} \sigma^2 &= \left(\frac{1-\beta_i^2}{\beta_i^2} + \frac{1}{1-\bar{\alpha}_{i-1}^2}\right)^{-1} \\ &= \frac{\beta_i^2 (1-\bar{\alpha}_{i-1}^2)}{\beta_i^2 + (1-\beta_i^2)(1-\bar{\alpha}_{i-1}^2)}\\ &= \beta_i^2 \frac{1-\bar{\alpha}_{i-1}^2}{1-\bar{\alpha}_i^2} \\ \mu &= \sigma^2 \left(\frac{1-\beta_i^2}{\beta_i^2} \cdot \frac{1}{\sqrt{1-\beta_i^2}} x_i + \frac{1}{1-\bar{\alpha}_{i-1}^2} \cdot \bar{\alpha}_{i-1} x_0\right)\\ &= \frac{\sqrt{1-\beta_i^2} (1-\bar{\alpha}_{i-1}^2)}{1-\bar{\alpha}_i^2} x_i + \frac{\beta_i^2 \bar{\alpha}_{i-1}}{1-\bar{\alpha}_i^2} x_0\\ &= \frac{\alpha_i (1-\bar{\alpha}_{i-1}^2)}{1-\bar{\alpha}_i^2} x_i + \frac{\bar{\alpha}_{i-1}\beta_i^2}{1-\bar{\alpha}_i^2} x_0\\ \end{aligned} \]
Thus, we have \[ p(x_{i-1}|x_i, x_0) = \mathcal{N}\left(x_{i-1}; \frac{\alpha_i (1-\bar{\alpha}_{i-1}^2)}{1-\bar{\alpha}_i^2} x_i + \frac{\bar{\alpha}_{i-1}\beta_i^2}{1-\bar{\alpha}_i^2} x_0, \beta_i^2 \frac{1-\bar{\alpha}_{i-1}^2}{1-\bar{\alpha}_i^2} I\right) \]
And the loss function for training DDPM is the sum of KL divergences: \[ \begin{aligned} \mathcal{L}_{\mathrm{DDPM}} &= \sum_{i=1}^{T} \mathbb E_{p(x_0) p_i(x_i|x_0)} [\mathrm{KL}(p(x_{i-1}|x_i, x_0) || p_{\phi}(x_{i-1}|x_i))] \\ &= \sum_{i=1}^{T} \frac{1}{\sigma_i^2}\mathbb E_{p(x_0) p_i(x_i|x_0)} \left[\| \mu_i(x_i, x_0, i) - \mu_{\phi}(x_i,i)\|^2\right] + C\\ \end{aligned} \] where \(\mu_i(x_i, x_0, i)\) is the mean of \(p(x_{i-1}|x_i, x_0)\) derived above and \(\mu_{\phi}(x_i,i)\) is the predicted mean by the neural network.
Reparameterization trick:
It is also common to parameterize the denoising model to predict the noise \(\epsilon\) added to \(x_0\) instead of predicting the mean \(\mu_{\phi}(x_i,i)\) directly since we have the relation \[ x_i = \bar{\alpha}_i x_0 + \sqrt{1-\bar{\alpha}_i^2} \epsilon \]
ELBO
\[ p_{\phi}(x_0) = \int p_{\phi}(x_0, x_{1:T}) dx_{1:T} = \int p_{\phi}(x_0|x_1) \prod_{i=2}^{T} p_{\phi}(x_{i-1}|x_i) p(x_T) dx_{1:T} \]
To make it ELBO, we introduce the forward process \(q(x_{1:T}|x_0)\) as the variational distribution to approximate the intractable true posterior \(p_{\phi}(x_{1:T}|x_0)\) and expand it by the conditional posterior:
\[ \log p_{\phi}(x_0) \geq \mathbb{E}_{q(x_{1:T}|x_0)}\left[\log \frac{p_{\phi}(x_0, x_{1:T})}{p(x_{1:T}|x_0)}\right] \] Use \[ p(x_{1:T}|x_0) = p(x_T|x_0) \prod_{i=2}^{T} p(x_{i-1}|x_{i}, x_0) \]
\[ \begin{aligned} \mathcal{L}_{\mathrm{ELBO}}&= \mathbb{E}_{p(x_{1:T}|x_0)}\left[\log p_{\phi}(x_0|x_1) + \sum_{i=2}^{T} \log p_{\phi}(x_{i-1}|x_i) + \log p(x_T) - \sum_{i=1}^{T} \log q(x_i|x_{i-1}) - \log p(x_T|x_0)\right] \\ &= \underbrace{\mathbb{E}_{p(x_1|x_0)} \left[\log p_{\phi}(x_0|x_1)\right]}_{\mathrm{Reconstruction}} + \underbrace{\mathbb{E}_{p(x_T|x_0)} \left[\log p(x_T) - \log p(x_T|x_0)\right]}_{\mathrm{Prior}} + \underbrace{\sum_{i=2}^{T} \mathbb{E}_{p(x_{i}|x_0)} \left[\mathrm{KL}(p(x_{i-1}|x_i, x_0) || p_{\phi}(x_{i-1}|x_i))\right]}_{\mathrm{Diffusion}} \\ \end{aligned} \]
Features of DDPM
Let’s consider \(x\)-prediction since it is easier to understand.
Assume we have the optimal denoising model in each step, i.e., \(p_{\phi}(x_{i-1}|x_i) = p(x_{i-1}|x_i)\), then we can recover \(x_0\) perfectly.
But the reality is we approximate the denoising step with a Gaussian distribution, so the optimal posterior mean \(\mu_i(x_i, i)\) is still an average of all possible \(x_{i-1}\) that can be mapped to the same \(x_i\).
Claim:
Although we circumvent predicting \(x_{T-1}\) directly by predicting \(x_0\) and then computing the posterior distribution. The optimal denoising mean \(\mu_i(x_i, x_0, i)\) is still the average of all possible \(x_{i-1}\) that can be mapped to the same \(x_i\).
Proof: \[ \begin{aligned} \mathbb{E}_{p(x_{t-1}|x_t)}[x_{t-1}] &= \mathbb{E}_{p(x_0|x_t)}[\mathbb{E}_{p(x_{t-1}|x_t, x_0)}[x_{t-1}]] \\ &= \mathbb{E}_{p(x_0|x_t)}[\mu_t(x_t, x_0, t)] \\ &= \mathbb{E}_{p(x_0|x_t)}[a_t x_t + b_t x_0] \\ &= a_t x_t + b_t \mathbb{E}_{p(x_0|x_t)}[x_0] \\ &= \mu_t(x_t, \mathbb{E}_{p(x_0|x_t)}[x_0], t) \\ \end{aligned} \] where \(a_t = \frac{\alpha_t (1-\bar{\alpha}_{t-1}^2)}{1-\bar{\alpha}_t^2}\) and \(b_t = \frac{\bar{\alpha}_{t-1}\beta_t^2}{1-\bar{\alpha}_t^2}\).
So we can just discuss it as the standard VAE/HVAE case.
A more theoretical analysis will be discussed when the differential equation perspective is introduced later.
3. Score-Based Perspective: From EBMs to NCSN
3.1 Energy-Based Models
EBMs define a distribution through an energy function \(E_{\phi}(x)\): \[ p_{\phi}(x) = \frac{\exp(-E_{\phi}(x))}{Z_{\phi}}, \quad Z_{\phi} = \int \exp(-E_{\phi}(x)) dx \] where the \(Z_{\phi}\) is the partition function that normalizes the distribution.
When we lower the energy of a region, the probability of that region increases, and its complement regions decrease in probability.
Probability mass is redistributed across the entire space rather than assigned independently to each region.
Training through MLE
\[ \begin{aligned} \mathcal{L}_{\mathrm{MLE}}(\phi) &= \mathbb{E}_{q(x)}[\log p_{\phi}(x)] \\ &= \mathbb{E}_{q(x)}[-E_{\phi}(x)] - \log Z_{\phi} \\ &= \mathbb{E}_{q(x)}[-E_{\phi}(x)] - \log \int \exp(-E_{\phi}(x)) dx \\ \end{aligned} \]
Intractable due to the partition function \(Z_{\phi}\), which requires integrating over the entire data space.
Score function
For a density \(p(x)\), its score function is defined as the gradient of the log-density with respect to \(x\):
\[ s(x):= \nabla_x \log p(x),\quad \mathbb R^D \to \mathbb R^D \]
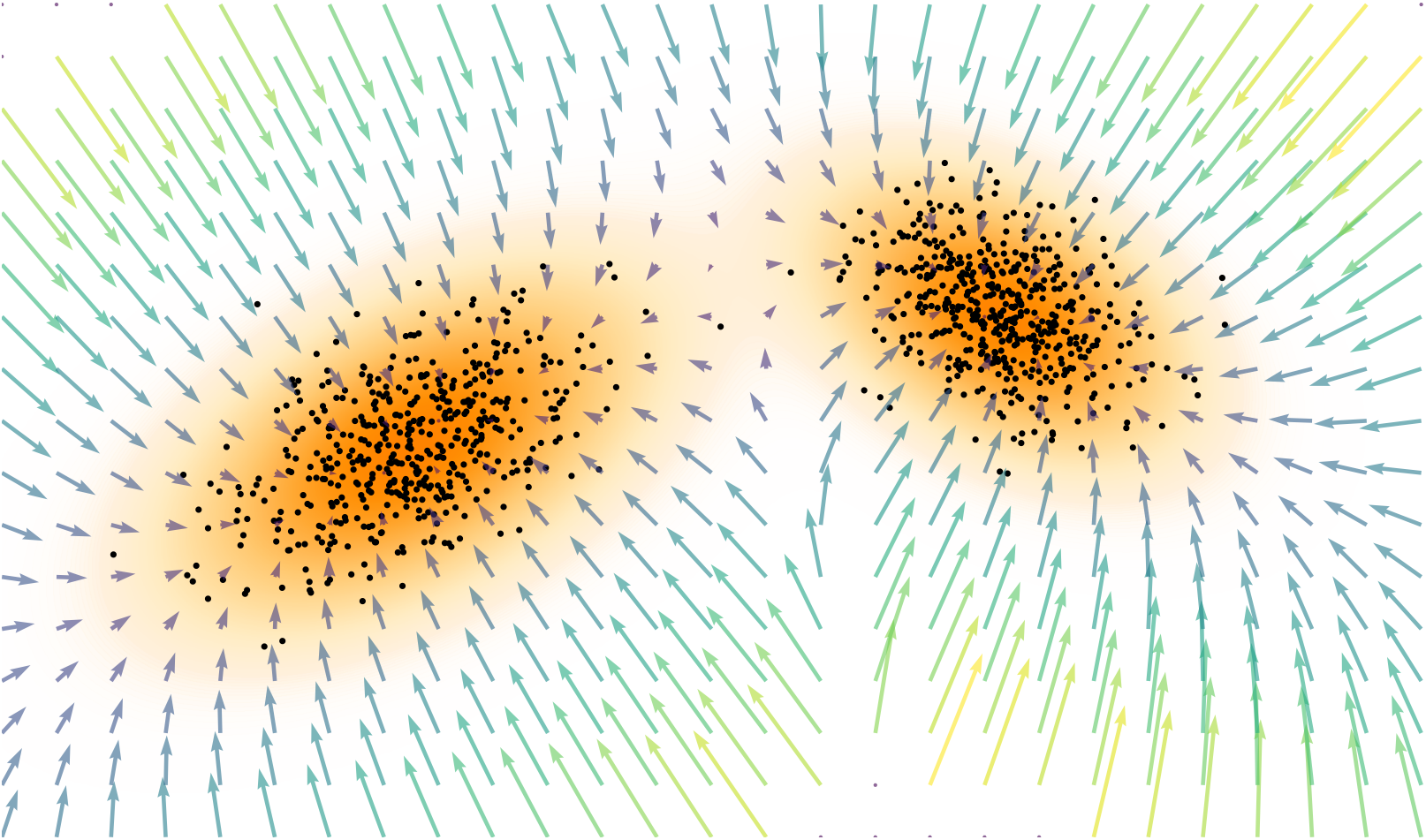
Score vector field points toward regions of higher data density.
Calculate the score function of EBM is irrelevant to the partition function: \[ \begin{aligned} s_{\phi}(x) &= \nabla_x \log p_{\phi}(x) \\ &= \nabla_x [-E_{\phi}(x) - \log Z_{\phi}] \\ &= -\nabla_x E_{\phi}(x) \\ \end{aligned} \]
And one can recover the density from the score function up to a constant: \[ \log p(x) = \log p(x_0) + \int_{0}^{1} s(x_0+ t(x - x_0))^{\top} (x - x_0) dt \]
Training EBM through Score Matching
\[ \mathcal{L}_{\mathrm{SM}}(\phi) = \mathbb{E}_{p_{data}(x)} \left[\| \nabla_x \log p_{\phi}(x) - \nabla_x \log p_{data}(x) \|_2^2\right] \]
And integration by parts gives an equivalent form that does not require \(\nabla_x \log p_{data}(x)\): \[ \mathcal{L}_{\mathrm{SM}}(\phi) = \mathbb{E}_{p_{data}(x)} \left[\mathrm{Tr}(\nabla_x^2 E_{\phi}(x)) + \frac{1}{2} \| \nabla_x E_{\phi}(x) \|_2^2\right] \] However, computing the Hessian trace \(\mathrm{Tr}(\nabla_x^2 E_{\phi}(x))\) is computationally expensive for high-dimensional data.
Langevin Sampling with Score Function
Without the partition function, we cannot directly sample from EBM. Instead, Langevin dynamics is used to generate samples.

Discrete-time Langevin dynamics: \[ \mathbf{x}_{n+1} = \mathbf{x}_n - \eta \nabla_{\mathbf{x}} E_{\phi}(\mathbf{x}_n) + \sqrt{\eta} \mathbf{\epsilon}_n, \quad \mathbf{\epsilon}_n \sim \mathcal{N}(0, I) \] where \(\eta>0\) is the step size.
Write in terms of score function: \[ \mathbf{x}_{n+1} = \mathbf{x}_n + \eta \nabla_{\mathbf{x}} \log p_{\phi}(\mathbf{x}_n) + \sqrt{\eta} \mathbf{\epsilon}_n \]
Continuous-time Langevin dynamics: \[ d\mathbf{x}(t) = \nabla_{\mathbf{x}} \log p_{\phi}(\mathbf{x}(t)) dt + \sqrt{2} d\mathbf{w}(t) \] where \(\mathbf{w}(t)\) is a Wiener process.
\(\sqrt{2}\) is used to ensure the stationary distribution is \(p_{\phi}(x)\). This will be explained in the differential equation appendix.
The intution is that the score term \(\nabla_{\mathbf{x}} \log p_{\phi}(\mathbf{x}(t)) dt\) pushes the sample toward high-density regions, while the noise term \(\sqrt{2} d\mathbf{w}(t)\) adds randomness to explore the space.
But Langevin dynamics is still struggling to sample from complex data distribution with many isolated modes, where it requires extremely long time to traverse low-density regions between modes.
3.2 From Energy-Based to Score-Based Generative Models
Once we have the score function, we can sample from the EBM using Langevin dynamics without computing the partition function. Therefore, we turn to directly learn the score function from data, leading to score-based generative models (SGMs).
\[ \boxed{ \mathcal{L}_{\mathrm{SM}}(\phi) = \mathbb{E}_{p_{data}(x)} \left[\| s_{\phi}(x) - s_{data}(x) \|_2^2\right] } \]
The tractable score matching loss is \[ \boxed{ \mathcal{L}_{\mathrm{SM}}(\phi) = \mathbb{E}_{p_{data}(x)} \left[\mathrm{Tr}(\nabla_x s_{\phi}(x)) + \frac{1}{2} \| s_{\phi}(x) \|_2^2\right] } \]
Proof of equivalence:
\[ \begin{aligned} \mathcal{L}_{\mathrm{SM}}(\phi) &= \mathbb{E}_{p_{data}(x)} \left[\| s_{\phi}(x)\|_2^2\right] - 2 \mathbb{E}_{p_{data}(x)} \left[s_{\phi}(x)^{\top} s_{data}(x)\right] + \mathbb{E}_{p_{data}(x)} \left[\| s_{data}(x) \|_2^2\right] \\ \end{aligned} \]
Focus on the second term: \[ \begin{aligned} \mathbb{E}_{p_{data}(x)} \left[s_{\phi}(x)^{\top} s_{data}(x)\right] &= \int p_{data}(x) s_{\phi}(x)^{\top} \nabla_x \log p_{data}(x) dx \\ &= \int s_{\phi}(x)^{\top} \nabla_x p_{data}(x) dx \\ &= \int \sum_{i=1}^{D} s_{\phi,i}(x) \frac{\partial p_{data}(x)}{\partial x_i} dx \\ &= \sum_{i=1}^{D} \left[ s_{\phi,i}(x) p_{data}(x) \Big|_{x_i=-\infty}^{x_i=+\infty} - \int p_{data}(x) \frac{\partial s_{\phi,i}(x)}{\partial x_i} dx \right] \\ &= - \mathbb{E}_{p_{data}(x)} \left[\mathrm{Tr}(\nabla_x s_{\phi}(x))\right] \\ \end{aligned} \]
The boundary term vanishes assuming \(p_{data}(x)\) decays to zero at infinity.
Note the third term is independent of \(\phi\), so we have the equivalence. \(\quad\square\)
3.3 Denoising Score Matching
Although the tractable score matching loss avoids computing the partition function, it still requires calculating the Hessian trace \(\mathrm{Tr}(\nabla_x s_{\phi}(x))\), which is computationally expensive for high-dimensional data at \(O(D^2)\) complexity.
Sliced Score Matching
Let \(\mathbf{u}\) be an isotropic random vector, i.e., \(\mathbb{E}[\mathbf{u}\mathbf{u}^{\top}] = I, \mathbb{E}[\mathbf{u}] = 0\).
Then we have \[ \begin{aligned} \mathrm{Tr}(A) &= \mathbb{E}[\mathbf{u}^{\top} A \mathbf{u}] \\ \mathbb{E}[(\mathbf{u}^{\top} s_{\phi}(x))^2] &= \| s_{\phi}(x) \|_2^2 \\ \end{aligned} \]
So the score matching loss can be rewritten as \[ \tilde{\mathcal{L}}_{\mathrm{SM}}(\phi) = \mathbb{E}_{x,u} \left[\mathbf{u}^{\top} \nabla_x s_{\phi}(x) \mathbf{u} + \frac{1}{2} (\mathbf{u}^{\top} s_{\phi}(x))^2\right] \]
This can be computed using the Jacobian-vector product (JVP) technique, which only requires \(O(D)\) complexity.
Note the method only control the score function along random directions at observed data points, providing weak control in their neighborhood.
Denoising Score Matching (DSM)
Sliced score matching still need to compute the Jacobian-vector product. And the random directions introduce variance in optimization.
Vincent et al. (2011) proposed denoising score matching (DSM) to avoid computing the Hessian trace.
The idea is to add noise to data and learn the score function of the noisy data distribution.
\[ p_{\sigma}(\mathbf{\tilde x}) = \int p_{data}(\mathbf{x}) p_{\sigma}(\mathbf{\tilde x}|\mathbf{x}) d\mathbf{x} \]
\[ \mathcal{L}_{\mathrm{SM}}(\phi; \sigma) = \mathbb{E}_{\mathbf{\tilde{x}} \sim p_{\sigma}} \left[\| s_{\phi}(\mathbf{\tilde{x}}; \sigma) - \nabla_{\mathbf{\tilde{x}}} \log p_{\sigma}(\mathbf{\tilde{x}}) \|_2^2\right] \]
This is equivalent to the denoising objective:
\[ \mathcal{L}_{\mathrm{DSM}}(\phi; \sigma) = \mathbb{E}_{\mathbf x \sim p_{data}(x),\mathbf{\tilde x} \sim p_{\sigma}(\cdot |x)} \left[\| s_{\phi}(\mathbf{\tilde x}) - \nabla_{\mathbf{\tilde x}} \log p_{\sigma}(\mathbf{\tilde x}|\mathbf{x}) \|_2^2\right] \]
Under Gaussian noise corruption \(p_{\sigma}(\mathbf{\tilde x}|\mathbf{x}) = \mathcal{N}(\mathbf{\tilde x}; \mathbf{x}, \sigma^2 I)\), we have \(\nabla_{\mathbf{\tilde x}} \log p_{\sigma}(\mathbf{\tilde x}|\mathbf{x}) = \frac{1}{\sigma^2} (\mathbf{x} - \mathbf{\tilde x})\).
The loss becomes
\[ \begin{aligned} \mathcal{L}_{\mathrm{DSM}}(\phi; \sigma) &= \mathbb{E}_{\mathbf x \sim p_{data}(x),\mathbf{\tilde x} \sim \mathcal{N}(\mathbf{x}, \sigma^2 I)} \left[\| s_{\phi}(\mathbf{\tilde x}) - \frac{1}{\sigma^2} (\mathbf{x} - \mathbf{\tilde x}) \|_2^2\right]\\ &=\mathbb{E}_{\mathbf x \sim p_{data}(x),\epsilon \sim \mathcal{N}(0, I)} \left[\| s_{\phi}(\mathbf{x} + \sigma \epsilon) + \frac{\epsilon}{\sigma} \|_2^2\right]\\ \end{aligned} \]
Tweedie’s Formula
Assume \(\mathbf{x} \sim p_{data}(\mathbf x)\) and \(\mathbf{\tilde x}|\mathbf{x} \sim \mathcal{N}(\ \cdot \ ;\alpha\mathbf{x}, \sigma^2 I)\).
Then we have: \[ \alpha \mathbb{E}_{\mathbf x \sim p(\mathbf x | \mathbf{\tilde x})}[\mathbf{x}|\mathbf{\tilde x}] = \mathbf{\tilde x} + \sigma^2 \nabla_{\mathbf{\tilde x}} \log p_{\sigma}(\mathbf{\tilde x}) \] where the expectation is over the posterior distribution \(p(\mathbf x | \mathbf{\tilde x}) = \frac{p_{data}(\mathbf x) p_{\sigma}(\mathbf{\tilde x}|\mathbf{x})}{p_{\sigma}(\mathbf{\tilde x})}\).
The proof is done by computing \(\nabla_{\mathbf{\tilde x}}\log p_{\sigma}(\mathbf{\tilde x})\) using Bayes’ theorem.
Higher cumulants of the posterior can also be computed through higher derivatives of \(\log p_{\sigma}(\mathbf{\tilde x})\).
Higher Order Tweedie’s Formula
Like \(\sigma\), assume the conditional law of \(\mathbf{\tilde x}|\mathbf{x}\) belongs to an exponential family with natural parameter \(\eta\): \[ q(\mathbf{\tilde x}|\mathbf{\eta}) = q_0(\mathbf{\tilde x}) \exp(\eta^{\top} \mathbf{\tilde x} - \psi(\mathbf{\eta})) \]
For Gaussian noise with variance \(\sigma^2 \mathbf I\), \(\mathbf\eta = \frac{\mathbf x}{\sigma^2}\), \(q_0(\mathbf{\tilde x}) = \frac{1}{(2\pi \sigma^2)^{D/2}} \exp(-\frac{\|\mathbf{\tilde x}\|^2}{2\sigma^2})\).
\[ \psi(\mathbf{\eta}) = \log \int q_0(\mathbf{\tilde x}) \exp(\eta^{\top} \mathbf{\tilde x}) d\mathbf{\tilde x} = \frac{\sigma^2}{2} \|\mathbf{\eta}\|^2 \]
is the log-partition function of the \(q(\mathbf{\tilde x}|\mathbf{\eta})\).
The observed data distribution is \[ p_{\eta}(\mathbf{\tilde x}) = \int p(\mathbf \eta) q(\mathbf{\tilde x}|\mathbf{\eta}) d\mathbf{\eta} \]
Define the log-partition function of \(p_{\eta}(\mathbf{\tilde x})\) as
\[ \lambda(\mathbf{\tilde x}) = \log p_{\mathbf{\eta}}(\mathbf{\tilde x}) - \log q_0(\mathbf{\tilde x}). \]
Then the posterior of \(\mathbf{\eta}\) given \(\mathbf{\tilde x}\) is \[ p(\mathbf{\eta}|\mathbf{\tilde x}) = \exp(\eta^{\top} \mathbf{\tilde x} - \psi(\mathbf{\eta}) - \lambda(\mathbf{\tilde x}))p(\mathbf{\eta}). \]
By Bayes’ theorem, \[ p(\mathbf{\eta}|\mathbf{\tilde x}) = \frac{p(\mathbf{\eta}) q(\mathbf{\tilde x}|\mathbf{\eta})}{p_{\eta}(\mathbf{\tilde x})} \propto p(\mathbf{\eta}) q(\mathbf{\tilde x}|\mathbf{\eta}) = p(\mathbf{\eta}) q_0(\mathbf{\tilde x}) \exp(\eta^{\top} \mathbf{\tilde x} - \psi(\mathbf{\eta})) = p(\mathbf{\eta}) \exp(\eta^{\top} \mathbf{\tilde x} - \psi(\mathbf{\eta}) - \lambda(\mathbf{\tilde x})) \]
The \(\lambda\) is the log-partition function of the posterior distribution.
For every \(\mathbf{\tilde x}\), we have \[ \int p(\mathbf{\eta}| \mathbf{\tilde x}) d\mathbf{\eta} = \int p(\mathbf{\eta}) \exp(\eta^{\top} \mathbf{\tilde x} - \psi(\mathbf{\eta}) - \lambda(\mathbf{\tilde x})) d\mathbf{\eta} = 1 \]
Taking derivatives with respect to \(\mathbf{\tilde x}\) on both sides gives \[ \begin{aligned} 0 &= \int p(\mathbf{\eta}) \exp(\eta^{\top} \mathbf{\tilde x} - \psi(\mathbf{\eta}) - \lambda(\mathbf{\tilde x})) (\mathbf{\eta} - \nabla_{\mathbf{\tilde x}} \lambda(\mathbf{\tilde x})) d\mathbf{\eta} \\ &= \mathbb{E}_{p(\mathbf{\eta}|\mathbf{\tilde x})}[\mathbf{\eta} - \nabla_{\mathbf{\tilde x}} \lambda(\mathbf{\tilde x})] \\ \end{aligned} \]
Thus, we have \[ \mathbb{E}_{p(\mathbf{\eta}|\mathbf{\tilde x})}[\mathbf{\eta}] = \nabla_{\mathbf{\tilde x}} \lambda(\mathbf{\tilde x}) \] Taking the second derivative gives \[ \mathrm{Cov}[\mathbf{\eta}|\mathbf{\tilde x}]=\mathbb{E}_{p(\mathbf{\eta}|\mathbf{\tilde x})}[(\mathbf{\eta} - \mathbb{E}_{p(\mathbf{\eta}|\mathbf{\tilde x})}[\mathbf{\eta}])(\mathbf{\eta} - \mathbb{E}_{p(\mathbf{\eta}|\mathbf{\tilde x})}[\mathbf{\eta}])^{\top}] = \nabla_{\mathbf{\tilde x}}^2 \lambda(\mathbf{\tilde x}) \]
Higher order cumulants can be derived similarly by taking higher order derivatives of \(\lambda(\mathbf{\tilde x})\), which is a \(k\)-th tensor for the \(k\)-th cumulant.
\[ \nabla_{\mathbf{\tilde x}}^k \lambda(\mathbf{\tilde x}) = \mathbb{E}_{p(\mathbf{\eta}|\mathbf{\tilde x})} \left[(\mathbf{\eta} - \mathbb{E}_{p(\mathbf{\eta}|\mathbf{\tilde x})}[\mathbf{\eta}])^{\otimes k}\right] = \kappa_k(\mathbf{\eta}|\mathbf{\tilde x}) \]
Denoising, Tweedie and SURE
Stein’s Unbiased Risk Estimator (SURE) provides an unbiased estimate of the mean squared error (MSE) between a denoised estimate and the true signal without access to the true signal.
\[ \tilde x = x + \sigma \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) \] A denoiser is any weakly differentiable function \(\mathbf{D}: \mathbb{R}^D \to \mathbb{R}^D\) that maps the noisy observation \(\tilde x\) to a denoised estimate \(\hat x = \mathbf{D}(\tilde x)\).
Quality of the denoiser is measured by the MSE: \[ R(\mathbf{D}; \mathbf x) = \mathbb{E}_{\tilde x | x}[\| \mathbf{D}(\tilde x) - x \|_2^2|x]. \]
The SURE states that the following quantity is an unbiased estimator of the MSE: \[ \mathrm{SURE}(\mathbf{D}; \tilde x) = \|\mathbf{D}(\tilde x) - \tilde x\|_2^2 + 2 \sigma^2 \nabla_{\tilde x}\cdot \mathbf{D}(\tilde x) - D \sigma^2 \]
For the proof, first use the identity \[ \mathbb{E}[\nabla_{\mathbf z} \cdot \mathbf{D}(\mathbf z)] ] = \mathbb{E}[\mathbf z^{\top} \mathbf{D}(\mathbf z)] \] by integration by parts on each component.
Therefore \[ \begin{aligned} \mathbb{E} [(\tilde x- x)^{\top} \mathbf{D}(\tilde x)]&=\sigma \mathbb{E}[\mathbf{z}^{\top} \mathbf{D}(\tilde x)] \\ &= \sigma \mathbb{E}[\nabla_{\mathbf z} \cdot \mathbf{D}(\mathbf x + \sigma \mathbf z)] \\ &= \sigma \mathbb{E}[\sigma \nabla_{\mathbf{\tilde x}} \cdot \mathbf{D}(\mathbf{\tilde x})] \\ &= \sigma^2 \mathbb{E}[\nabla_{\mathbf{\tilde x}} \cdot \mathbf{D}(\mathbf{\tilde x})] \end{aligned} \]
And then expand the MSE: \[ \begin{aligned} R(\mathbf{D}; \mathbf x) &= \mathbb{E}_{\tilde x | x}[\| \mathbf{D}(\tilde x) - x \|_2^2|x] \\ &= \mathbb{E}_{\tilde x | x}[\| \mathbf{D}(\tilde x) - \tilde x + \tilde x - x \|_2^2|x] \\ &= \mathbb{E}_{\tilde x | x}[\| \mathbf{D}(\tilde x) - \tilde x \|_2^2 |x] + 2 \mathbb{E}_{\tilde x | x}[(\tilde x - x)^{\top} (\mathbf{D}(\tilde x)- \tilde x) |x] + \mathbb{E}_{\tilde x | x}[\| \tilde x - x \|_2^2|x] \\ &= \mathbb{E}_{\tilde x | x}[\| \mathbf{D}(\tilde x) - \tilde x \|_2^2 |x] + 2 \left(\sigma^2 \mathbb{E}_{\tilde x | x}[\nabla_{\mathbf{\tilde x}} \cdot \mathbf{D}(\mathbf{\tilde x}) |x] - \mathbb{E}_{\tilde x | x}[(\tilde x - x)^{\top} \tilde x |x]\right) + \mathbb{E}_{\tilde x | x}[\| \tilde x - x \|_2^2|x] \\ &= \mathbb{E}_{\tilde x | x}[\| \mathbf{D}(\tilde x) - \tilde x \|_2^2 |x] + 2 \sigma^2 \mathbb{E}_{\tilde x | x}[\nabla_{\mathbf{\tilde x}} \cdot \mathbf{D}(\mathbf{\tilde x}) |x] - 2 \sigma^2 D + D \sigma^2 \\ &= \mathbb{E}_{\tilde x | x}[\mathrm{SURE}(\mathbf{D}; \tilde x) |x] \end{aligned} \]
\[ \mathbb{E}_{\tilde x | x}[\mathrm{SURE}(\mathbf{D}; \tilde x)] = \mathbb{E}_{\tilde x | x}[\| \mathbf{D}(\tilde x) - x \|_2^2] \]
\[ \begin{aligned} \mathbb{E}_{(\tilde x, x)}[\| \mathbf{D}(\tilde x) - x \|_2^2] &= \mathbb{E}_{x} [\mathbb{E}_{\tilde x | x}[\| \mathbf{D}(\tilde x) - x \|_2^2]] \\ &= \mathbb{E}_{x} [\mathbb{E}_{\tilde x | x}[\mathrm{SURE}(\mathbf{D}; \tilde x)]] \\ &= \mathbb{E}_{\tilde x} [\mathrm{SURE}(\mathbf{D}; \tilde x)] \\ \end{aligned} \]
On the other hand \[ \begin{aligned} \mathbb{E}_{(\tilde x, x)}[\| \mathbf{D}(\tilde x) - x \|_2^2] &= \mathbb{E}_{\tilde x} [\mathbb{E}_{x | \tilde x}[\| \mathbf{D}(\tilde x) - x \|_2^2]] \\ \end{aligned} \] Pointwise minimization of the MSE gives \[ \mathbf{D}^*(\tilde x) = \mathbb{E}[x|\tilde x] \] for almost every \(\tilde x\).
By Tweedie’s formula, we have \[ \mathbf{D}^*(\tilde x) = \tilde x + \sigma^2 \nabla_{\tilde x} \log p_{\sigma}(\tilde x) \]
Therefore, we deduce \[ \frac{1}{2\sigma^4} \mathrm{SURE}(\mathbf{D}; \tilde x) = \mathrm{Tr}(\nabla_{\tilde x} s_{\phi}(\tilde x)) + \frac{1}{2} \| s_{\phi}(\tilde x) \|_2^2 + C(\sigma) \]
This shows the equivalence between denoising, score matching and SURE up to a constant depending on \(\sigma\).
Generalized Score Matching
Omitted. TODO.